Por Qué Construimos YouBase sobre Cloudflare Workers
January 29, 2026
11 mins de lectura
Construimos YouBase —una Plataforma como Servicio donde los agentes de codificación con IA pueden desplegar y gestionar aplicaciones web de pila completa. No solo llamar APIs, sino realmente escribir código, desplegarlo, probarlo, iterarlo y volver a desplegarlo. Piensa en Vercel o Heroku, excepto que tu "desarrollador" es Claude o GPT.
El desafío técnico era evidente desde el principio: los agentes de IA iteran rápido. Despliegan código, golpean un endpoint, obtienen un error, lo corrigen, vuelven a desplegar, a veces docenas de veces por hora. Las plataformas tradicionales no están diseñadas para ese tipo de ciclo de retroalimentación tan ajustado. Necesitábamos despliegues que se completaran en segundos, distribución global por defecto y un fuerte aislamiento multi-tenant, porque el código que se despliega no es de confianza y se genera sobre la marcha.
Tampoco queríamos construir desde cero un sistema de orquestación, una capa de replicación o un marco de aislamiento multi-tenant.
Elegimos Cloudflare Workers y lanzamos a producción en aproximadamente dos meses.
Dos semanas después del lanzamiento, necesitamos actualizar la lógica de validación en todos los Workers de tenants activos. En una plataforma tradicional, eso habría requerido despliegues escalonados coordinados, lanzamientos por fases y una larga cola de rezagados. Con nuestra configuración, redesplegamos un único Worker de Service Bindings. Unos treinta segundos después, todos los tenants ejecutaban la nueva lógica, sin tiempo de inactividad y sin redespliegues de tenants. Ese fue el momento en que la arquitectura dejó de ser teórica.
Visión General de la Arquitectura
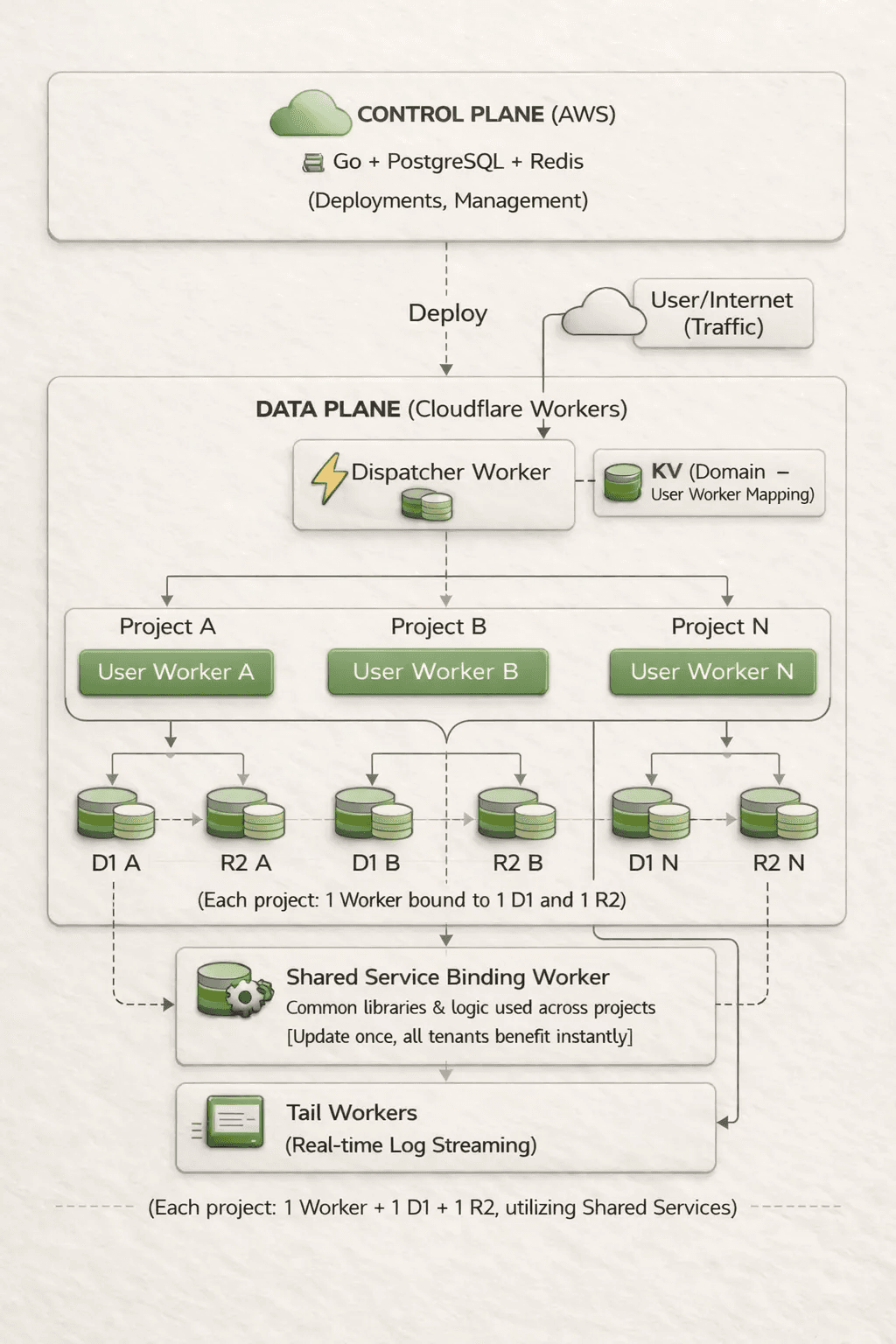
YouBase funciona sobre una arquitectura híbrida. El plano de control (Go, PostgreSQL, Redis, Lambda, etc.) gestiona la creación de proyectos, los despliegues, la facturación y la administración. El plano de datos se ejecuta completamente en Cloudflare Workers.
Cada proyecto obtiene su propio Worker con una base de datos D1 dedicada y un bucket R2 dedicado. No hay base de datos compartida ni almacenamiento compartido. Los bindings son por tenant, así que si un Worker se comporta mal, no puede acceder al estado de otro tenant.
Un Worker dispatcher enruta las solicitudes entrantes al Worker del tenant correcto usando mapeos de dominio almacenados en KV. También ejecutamos un Worker compartido que proporciona lógica común a través de Service Bindings, incluyendo validación, reglas de facturación, utilidades del framework y feature flags.
No gestionamos regiones, réplicas ni grupos de nodos. Todo se ejecuta automáticamente en más de 300 ubicaciones de Cloudflare.
A Hombros de Cloudflare
Workers for Platforms: Multi-Tenancy Sin Orquestación
Necesitábamos un multi-tenancy real. Con Kubernetes, eso habría significado políticas de red, pods por tenant, cuotas de recursos, gestión de secretos, bases de datos por tenant y mucha sobrecarga operacional.
Workers for Platforms ofrece el aislamiento multi-tenant como una característica nativa del runtime. Cada workspace obtiene un namespace de despacho con sus propios Workers y bindings. Nuestro dispatcher lee los mapeos de dominio desde KV y reenvía las solicitudes al Worker correcto:
Cada Worker se ejecuta en su propio aislado V8. Los tenants no pueden acceder a los bindings ni a la memoria de los demás. No hay sistema de archivos compartido ni entorno compartido.
Lo que nos sorprendió no fue el aislamiento en sí, sino lo poca infraestructura que tuvimos que configurar. No aprovisionamos clústeres. No configuramos redes. No elegimos regiones. Creamos namespaces y desplegamos Workers.
La principal fricción aquí fue depurar el enrutamiento de namespaces. Los fallos en la ruta de despacho suelen aparecer como errores genéricos de fetch con contexto de pila limitado. Terminamos añadiendo cabeceras de correlación para poder rastrear solicitudes desde el dispatcher, al Worker del tenant, hasta el Worker compartido.
Incluso con esa aspereza, este enfoque fue dramáticamente más simple que ejecutar Kubernetes para código no confiable y generado dinámicamente.
D1 + Session API: Consistencia en el Edge
Las bases de datos en el edge suelen intercambiar consistencia por latencia, y ese compromiso no era aceptable para nuestro caso de uso.
La Session API de D1 resuelve esto con marcadores de posición. Después de cada escritura, la base de datos devuelve un bookmark (una posición en el log de transacciones). Si envías ese bookmark en la siguiente solicitud, D1 garantiza que leerás tus propias escrituras:
Pasamos los bookmarks a través de cabeceras de solicitud. Nuestro framework los extrae, crea sesiones D1, ejecuta consultas y devuelve el nuevo bookmark.
Esto nos da sólidas garantías de lectura tras escritura sin servidores de coordinación. Todas las escrituras van al primario para consistencia. Las lecturas van a la réplica más cercana para velocidad. Si una réplica no ha alcanzado tu bookmark todavía, espera.
Operacionalmente, esto fue mucho más simple que gestionar réplicas de PostgreSQL y depurar el lag de replicación entre regiones.
Service Bindings: Lógica Compartida con Actualizaciones Instantáneas
El problema operacional que más nos preocupaba era actualizar la lógica compartida a medida que crecía el número de Workers.
Reglas de seguridad. Validación. Facturación. Límites de tasa. Feature flags.
La respuesta tradicional son actualizaciones escalonadas en todos los Workers de tenants.
Service Bindings nos permiten ejecutar un único Worker compartido al que los Workers de tenants llaman a través de RPC nativo. No hay capa HTTP, no hay autenticación por token, y el overhead es de menos de un milisegundo.
Usamos este Worker compartido para:
Validación de SQL
Cálculos de facturación
Limitación de tasa
Feature flags
Utilidades del framework
Reglas de negocio centrales
Otras preocupaciones de infraestructura compartida
Cuando actualizamos este Worker, todos los tenants ven inmediatamente el nuevo comportamiento.
Este es el componente que eliminó la mayor parte de la carga operacional. Hoy, una gran fracción de las solicitudes de tenants fluye a través de Service Bindings.
Observabilidad: Tail Workers y Analytics Engine
No podíamos pedirles a los usuarios que instrumentaran los logs. Los agentes de IA generan código que puede fallar, entrar en bucle o comportarse de manera extraña. Necesitábamos logs y métricas que funcionaran "fuera de la caja".
Tail Workers capturan la salida de consola, excepciones, metadatos de solicitudes e información de temporización. Construimos un servicio de ingesta que almacena en buffer estos eventos y los transmite a los clientes a través de SSE. Los usuarios ejecutan edgespark log tail y ven la salida en vivo con latencia inferior a un segundo.
Analytics Engine cubre el lado de las métricas. Rastreamos dimensiones por proyecto, por dominio y por endpoint. Los sistemas tradicionales se desmoronan a ese nivel de cardinalidad.
Las escrituras son no bloqueantes, y los resultados se pueden consultar a través de SQL sin una explosión de cardinalidad.
Usamos esto para dashboards, facturación, informes de uso y limitación de tasa.
Infraestructura de Soporte: R2 y KV
R2 proporciona almacenamiento de objetos compatible con S3. Cada proyecto obtiene un bucket dedicado. Las URLs prefirmadas, las cargas multiparte y el streaming funcionan como se espera.
KV almacena los mapeos de enrutamiento dominio-worker. El dispatcher consulta KV en cada solicitud y las actualizaciones se propagan globalmente en segundos.
Por Qué Importa la Plataforma Integrada
Esta integración importó en la práctica porque no pasamos semanas conectando Lambda, RDS, S3 y API Gateway. No escribimos lógica de connection pooling ni configuramos endpoints de VPC. No configuramos políticas IAM entre servicios ni ejecutamos nuestra propia base de datos de series temporales para métricas.
Los Workers llaman a D1 y R2 a través de bindings. Service Bindings conectan Workers con RPC nativo. KV gestiona el enrutamiento. Tail Workers capturan logs. Analytics Engine ingesta métricas. Las piezas encajan limpiamente.
En la práctica, eso significó que pasamos la mayor parte de esos dos meses construyendo producto en lugar de infraestructura.
Conclusiones Técnicas
Éramos escépticos sobre SQLite en el edge, pero D1 con la Session API nos demostró que estábamos equivocados. Nos dio datos globales y consistentes con menos complejidad operacional que las réplicas de PostgreSQL.
El multi-tenancy se convirtió en un problema de configuración en lugar de un problema de arquitectura. Cuando el runtime soporta el aislamiento a través de aislados V8 y namespaces de despacho, no necesitas construir el aislamiento tú mismo.
Service Bindings resolvió el problema operacional de actualizar la lógica compartida. Un despliegue actualiza las reglas de seguridad, las utilidades y las funcionalidades principales en todos los tenants.
Las restricciones de la plataforma en realidad mejoraron nuestro diseño. Sin procesos de larga duración. Sin sistema de archivos. SQLite en lugar de Postgres. Esas restricciones nos empujaron hacia patrones más simples y confiables.
La parte difícil no fue Cloudflare en sí — fue comprometerse con ello. Pasamos más tiempo evaluando alternativas de lo que tardamos en depurar problemas de producción.
También esperábamos que la observabilidad tomara semanas. Tail Workers y Analytics Engine nos tuvieron en marcha en unos pocos días.
Depurar Workers distribuidos a escala es más difícil de lo que esperábamos. Las herramientas no son tan maduras como en los entornos de servidor tradicionales. Pero la compensación en simplicidad operacional vale la pena.
Limitaciones Actuales
D1 tiene un límite de 10 GB por base de datos. Eso funciona bien para la mayoría de las aplicaciones de producción, pero no para cargas de trabajo con muchos datos.
Los Workers tienen un límite de 300 segundos de tiempo de CPU por solicitud HTTP. Las tareas de larga duración requieren patrones asíncronos o procesamiento en segundo plano.
Los WebSockets requieren Durable Objects para estado persistente. La arquitectura actual es solo solicitud-respuesta, por lo que las funcionalidades en tiempo real como presencia o cursores en vivo necesitan infraestructura adicional.
El tail en vivo actualmente solo es compatible con entornos de staging. La retención y consulta de logs de producción requieren sistemas de almacenamiento e indexación separados.
Estas son restricciones de la plataforma con las que trabajamos hoy.
Hoja de Ruta Futura
Estamos integrando Cron Triggers para trabajos programados en segundo plano como limpieza de bases de datos, generación de informes y agrupación de notificaciones.
Para la colaboración en tiempo real, estamos evaluando Durable Objects para el manejo de WebSockets, sistemas de presencia y sincronización de estado.
Para soportar aplicaciones con muchos datos, estamos añadiendo soporte para PostgreSQL y MySQL, con Workers de tenants accediendo a bases de datos externas a través de pooling seguro.
También estamos ampliando el uso de Analytics Engine para métricas de negocio de nivel superior, como popularidad de endpoints de API, uso de funcionalidades y patrones de errores.
El plano de datos en el edge ya escala globalmente. Estos esfuerzos se centran en las capacidades del plano de control y las brechas restantes de la plataforma a medida que los primitivos subyacentes continúan evolucionando.
Conclusión
Construimos YouBase sobre Cloudflare Workers porque no queríamos pasar seis meses en infraestructura antes de lanzar el producto. Dos meses después, estábamos en producción con arranques en frío de milisegundos, lecturas consistentes en el edge y observabilidad automática.
Todavía hay asperezas. Depurar Workers distribuidos es más difícil que depurar un monolito, y algunos límites de la plataforma requieren soluciones alternativas. Estamos construyendo soluciones híbridas para las áreas donde Workers no encaja del todo todavía.
Pero no hemos tenido que reconstruir la infraestructura central desde el lanzamiento. Hasta ahora, ha manejado la carga de trabajo para la que fue diseñada. Cuando necesitamos actualizar en todos los tenants, tardó unos 30 segundos. Ese es el compromiso que importó.
Apéndice Técnico: Tecnologías de Cloudflare Utilizadas
Stack del Plano de Datos:
Cloudflare Workers – Cómputo serverless basado en aislados V8 en el edge
Workers for Platforms – Despliegue de workers multi-tenant con namespaces de despacho
Cloudflare D1 – Base de datos en el edge basada en SQLite con Session API para consistencia
Cloudflare R2 – Almacenamiento de objetos compatible con S3 con acceso global desde el edge
Cloudflare Service Bindings – Comunicación worker-a-worker de baja latencia estilo RPC
Cloudflare KV – Almacenamiento clave-valor para enrutamiento de dominios
Tail Workers – Transmisión de logs en tiempo real y observabilidad
Analytics Engine – Métricas de cardinalidad ilimitada con consultas SQL
Stack del Plano de Control:
Runtime: Go con framework Hertz
Base de datos: PostgreSQL para el estado del plano de control
Caché: Redis para sesiones y limitación de tasa
Serverless: AWS Lambda para tareas asíncronas
Framework Orientado al Usuario:
Framework HTTP: Hono (ligero, optimizado para el edge)
ORM: Drizzle ORM (SQL con seguridad de tipos con adaptador D1)
Autenticación: Better Auth con soporte nativo para D1