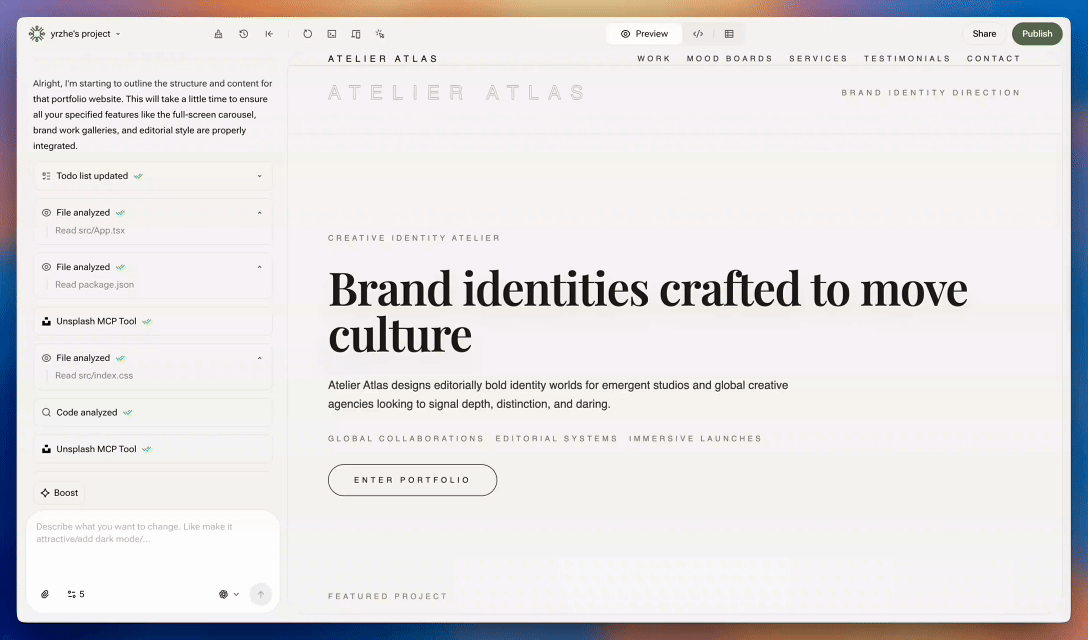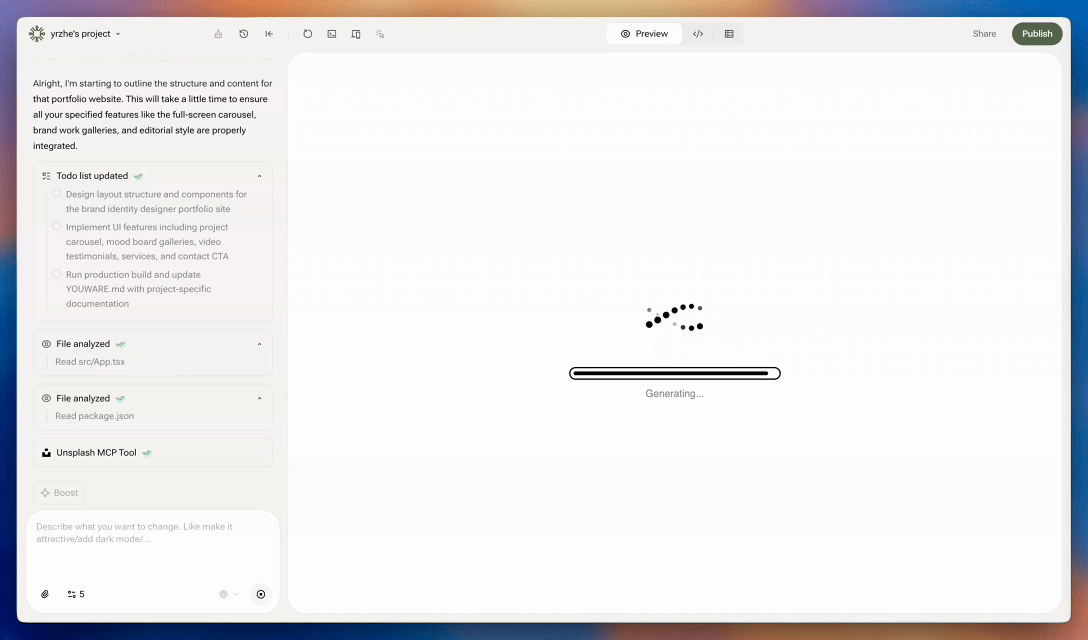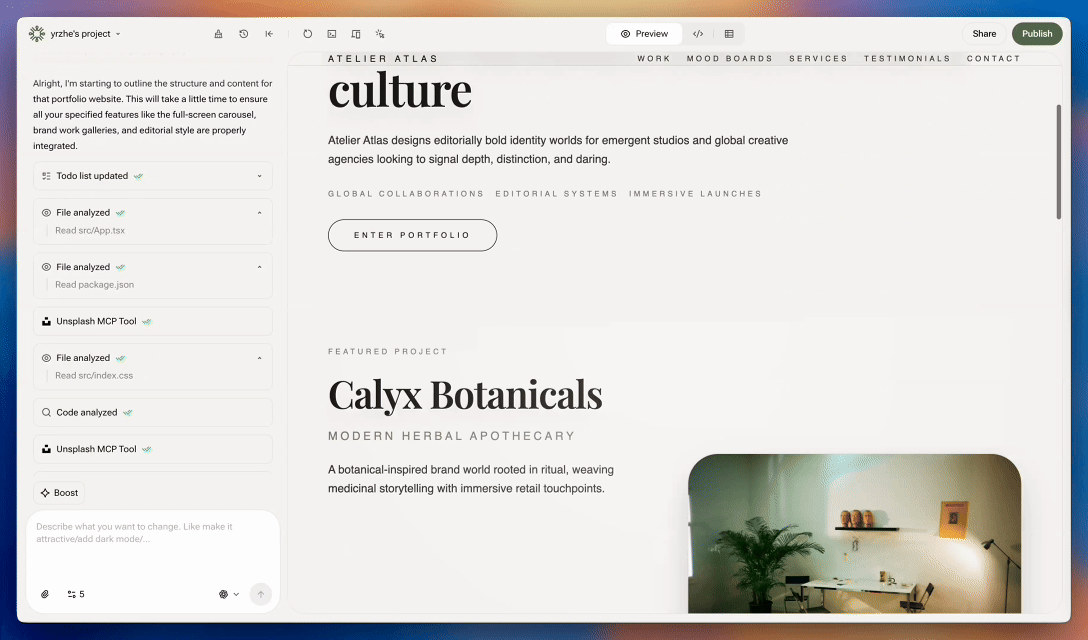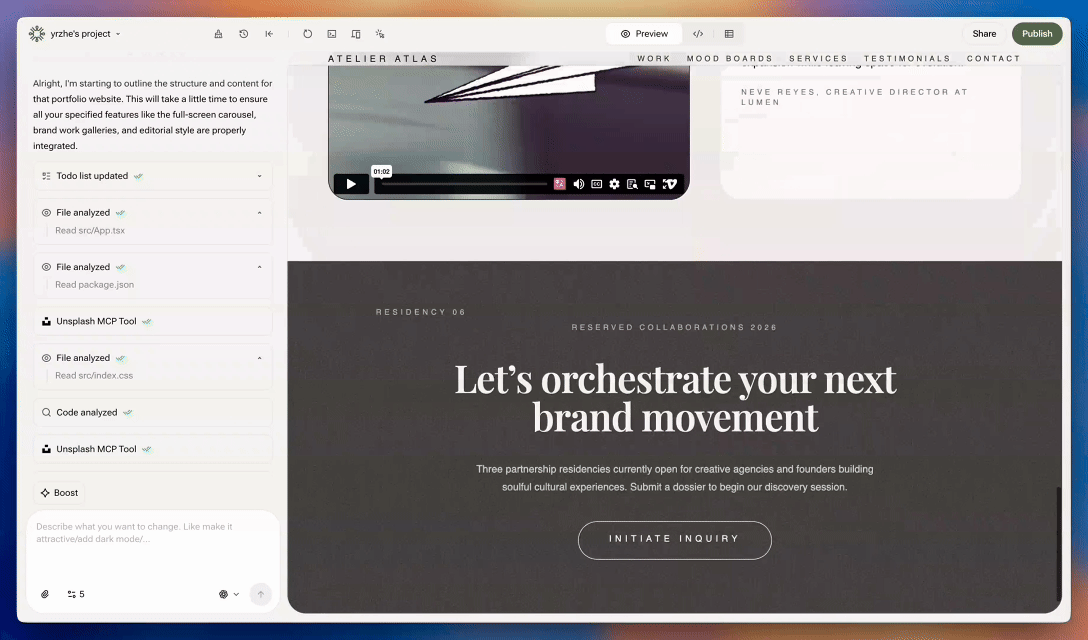
Todo el mundo sufre de Fatiga por Degradado Morado. Y sabemos a quién culpar. Hace cinco años, el creador de Tailwind CSS —el framework que básicamente sostiene la web moderna de IA— tomó una decisión fatídica: estableció el color de interfaz predeterminado en bg-indigo-500. Una elección que, sin saberlo, definiría la estética de toda una generación de IA.
Aquí entra Anthropic, que tomó esta estética morada y la llevó al extremo. Su modelo insignia, Claude Sonnet, parece tener una conexión profunda y espiritual con ese color. No importa cuán detallado sea tu prompt de diseño ni cuánto supliques: siempre te sirve otro sitio web con degradado morado.
En YouWare usamos mucho Sonnet. Tanto, que nuestro propio sitio empezó a parecer un tributo al color morado. Esta es la historia de cómo nos liberamos.
El Parche del Botón "Boost"
Nuestro primer plan de escape fue una función que llamamos "Boost".
Los system prompts para agentes de IA son largos y delicados. No puedes simplemente decirle a una IA "hazlo ver bien" y esperar una obra maestra. Por eso creamos un modo especial llamado "Boost". Cuando el usuario lo activa, el agente cambia a un conjunto curado de pautas de diseño moderno, dándole al proyecto una mejora estética instantánea y, lo más importante, un exorcismo de la plaga morada.
Boost es una función excelente que hace maravillas, especialmente en proyectos nuevos. Pero a medida que la gente lo usó, aprendimos dos cosas:
Compartir
¿Listo para crear?
Es un Gran Compromiso: Hacer clic en "Boost" es como redecorar todas las habitaciones de tu casa de golpe. Es un salto de fe. Como los usuarios no siempre sabían qué esperar, algunos dudaban en aplicar un cambio tan grande a un proyecto en el que ya habían invertido trabajo.
Puede Ser Disruptivo: En sitios web más complejos, una renovación total del sistema de diseño puede generar turbulencias. Aunque no rompe el sitio, puede introducir desajustes de maquetación o inconsistencias de estilo que requieren corrección manual.
Si bien Boost sigue siendo una herramienta valiosa en nuestro arsenal —ideal para arrancar proyectos nuevos con una estética sólida y sin morado—, nos enseñó una lección crucial: solo puedes llegar hasta cierto punto con prompts y posprocesamiento. Un parche puede cubrir una herida, pero no puede curarla. La verdadera batalla tenía que darse en el modelo base.
Si No Puedes Evaluarlo, No Puedes Mejorarlo
Pero ¿cómo se libra una batalla a nivel de modelo? No puedes arreglar lo que no puedes medir. Para encontrar un mejor modelo base —uno que no use degradados morados por defecto— necesitábamos una forma rigurosa de comparar modelos objetivamente. Necesitábamos un framework de evaluación sistemático.
En YouWare, tratamos las evaluaciones con cierta reverencia. Construimos una plataforma de evaluación automatizada para uso interno. No es elegante, pero es efectiva.
Cuando se lanza un modelo nuevo, basta con unos pocos clics para ejecutar un conjunto completo de casos de prueba. Usamos la técnica LLM-as-a-judge para puntuar los resultados y construir nuestro propio leaderboard interno, algo parecido a LMArena.
Para resolver el inevitable sesgo de un juez de IA, también etiquetamos los datos nosotros mismos. Eso mantiene el sistema honesto. Este esfuerzo nos da un sólido sistema de evaluación automatizada que cubre cada parte de la generación de sitios web, con sub-rankings para:
Visuales: por ejemplo, ¿parece diseñado en 2025 o en 2015?
Función: por ejemplo, ¿funciona el botón de "Contáctenos"?
Requisitos: por ejemplo, ¿recordó el sistema que pediste un "diseño minimalista y brutalista para una cafetería de gatos"?
Durante mucho tiempo, Claude fue el rey de nuestros benchmarks internos.
Sus diseños eran completos. Y tenía su propio sistema de diseño coherente (aunque morado), algo que la mayoría de los otros modelos no tenía.
Una Nueva Esperanza (y un Nuevo Dolor de Cabeza)
El 7 de agosto de 2025, se lanzó GPT-5.
Lo probamos de inmediato, pero los resultados fueron agridulces. Era el primer modelo que siquiera se acercaba al nivel de calidad de Sonnet. Pero solo en la variante gpt-5-high. Piénsalo como subir la configuración gráfica de un videojuego a "Ultra": los visuales son impresionantes, pero los fotogramas por segundo se desploman. Y era lento. Muy, muy lento.
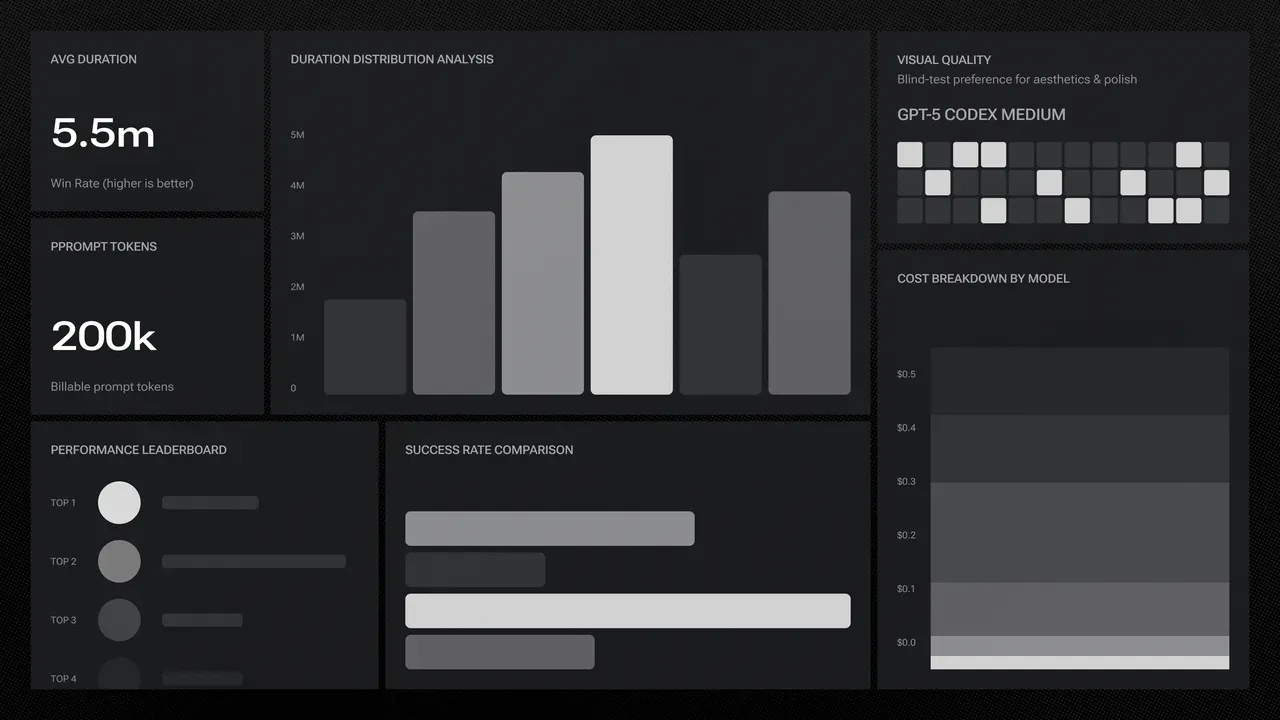
Claude Sonnet: 5 a 6 minutos para generar un sitio.
GPT-5-High: casi 20 minutos.
Veinte minutos es una eternidad en términos de internet. Eso hacía a GPT-5-High inusable. Pero en septiembre apareció un nuevo contendiente: GPT-5-Codex.
Toda la empresa se enamoró del modelo "Codex" en el CLI de inmediato. Era rápido, inteligente y podía ajustar su razonamiento de forma dinámica. Pero no había API. Así que esperamos. Una semana después, llegó la API y ejecutamos nuestras evaluaciones.
Cuando llegaron los resultados, pensamos que nuestro sistema estaba roto. Por primera vez, un modelo había destronado a Claude. Era más rápido, más barato y, lo más importante, su puntuación visual aplastaba la de Sonnet.
Para asegurarnos, revisamos los resultados manualmente, lado a lado. Eran las 10 de la noche y la oficina resonaba con un constante "¡Increíble!" y "¡No puede ser!". Codex generaba sitios web con diseños modernos, premium y centrados en la marca. Parecían hechos por humanos. Al día siguiente, pusimos Codex en producción. El reinado del morado había terminado.
La Última Milla Siempre Es la Más Extraña
Entonces, tuvimos nuestro final feliz, ¿verdad? No tan rápido.
Codex es un genio, pero uno raro y psicodélico. La gente en X (antes Twitter) parece estar de acuerdo.
https://x.com/willccbb/status/1973178973027967132
Es un modelo con mucho ajuste por RL que es extraordinario en programación y bastante malo en todo lo demás.
Es extraño con el llamado de herramientas. Dale una herramienta y encontrará la forma más inesperada de usarla. Lo hemos visto intentar usar nuestra herramienta de navegación web para hacer solicitudes HTTP a la documentación oficial de Node.js.
Sobrepensaba todo. Hazle una pregunta difícil y podría pasarse una hora revisando cada archivo de tu proyecto antes de darte una respuesta.
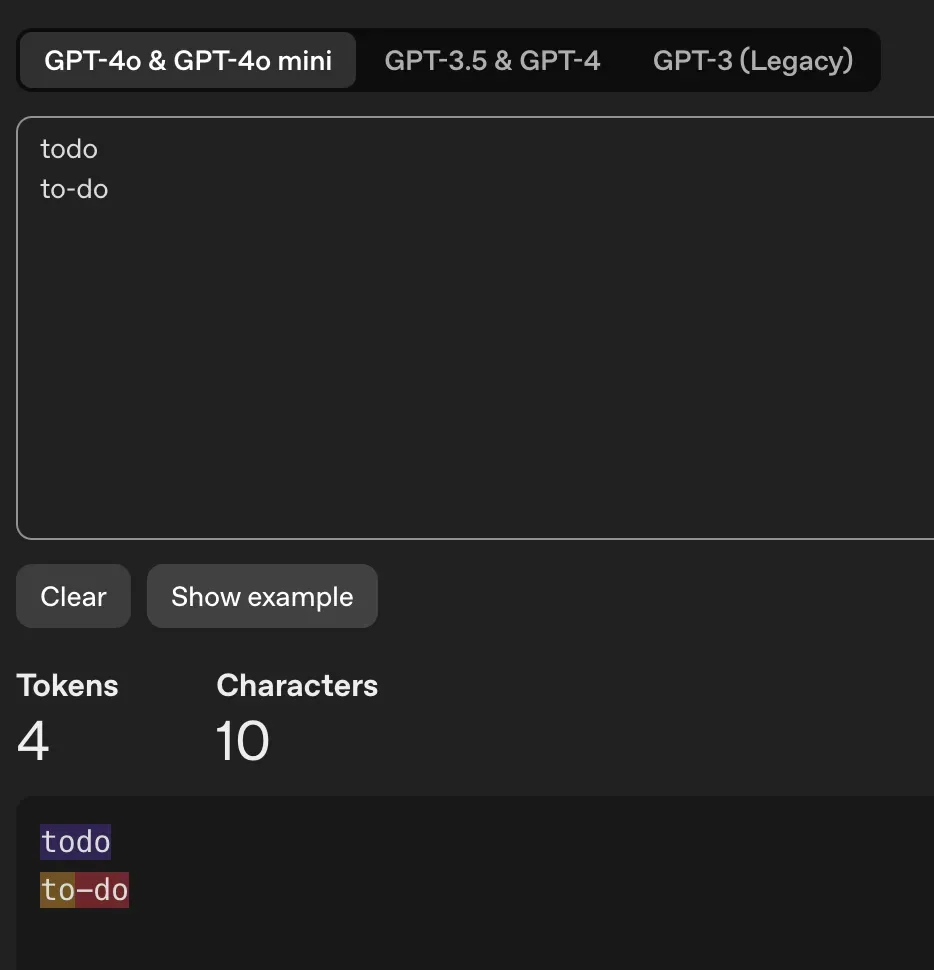
Empezaba a hablar en español de forma aleatoria. Este fue el bug más extraño. Un usuario escribía en inglés, y Codex respondía en español fluido. Pasamos semanas depurando esto. ¿La causa? Una de nuestras herramientas internas se llamaba todo_write. "Todo" es una palabra común en español que significa "all". El modelo se confundía con el nombre de esa herramienta. La renombramos a to_do_write y el problema desapareció.
En la visión de GPT, 'todo' es una sola palabra; 'to-do' son dos palabras.
Como Codex es tan poderoso pero tan peculiar, tuvimos que rediseñar todo nuestro sistema de prompts y herramientas para adaptarnos a él. La Guía de Prompts de OpenAI para GPT-5-Codex fue un salvavidas, ya que enfatizaba que Codex no es un reemplazo directo de otros modelos.
La Vida Después del Morado
Tras semanas de arduo trabajo, optimizamos nuestro sistema para Codex, reduciendo el tiempo de generación en un 50% y los costos en un 70%, sin sacrificar el rendimiento.
Fue un camino largo y extraño, pero valió la pena. Ahora, nuestros usuarios pueden obtener un sitio web con un diseño de primer nivel —sin morado— por apenas unos centavos. Y creemos que eso importa mucho.
Cómo Eliminamos el Degradado Morado en Frontends de IA