
Por Que Construímos o YouBase no Cloudflare Workers
Construímos o YouBase — uma Plataforma como Serviço (PaaS) onde agentes de IA podem implantar e gerenciar aplicações web full-stack. Não apenas chamar APIs, mas realmente escrever código, publicar, testar, iterar e reimplantar. Pense no Vercel ou Heroku, exceto que o seu "desenvolvedor" é o Claude ou o GPT.
O desafio técnico era evidente desde o início: agentes de IA iteram rápido. Eles implantam código, atingem um endpoint, encontram um erro, corrigem, reimplantam — às vezes dezenas de vezes por hora. Plataformas tradicionais não foram criadas para esse tipo de ciclo de feedback acelerado. Precisávamos de implantações que fossem concluídas em segundos, distribuição global por padrão e isolamento multi-tenant robusto, porque o código sendo implantado é não confiável e gerado em tempo real.
Também não queríamos construir um sistema de orquestração, uma camada de replicação ou um framework de isolamento multi-tenant do zero.
Escolhemos o Cloudflare Workers e chegamos à produção em cerca de dois meses.
Duas semanas após o lançamento, precisamos atualizar a lógica de validação em todos os Workers de tenants ativos. Em uma plataforma tradicional, isso exigiria deploys graduais coordenados, rollouts em estágios e uma longa cauda de instâncias desatualizadas. Com nossa configuração, reimplantamos um único Worker de Service Bindings. Cerca de trinta segundos depois, todos os tenants estavam executando a nova lógica, sem downtime e sem reimplantações de tenant. Foi nesse momento que a arquitetura deixou de ser teórica.
Visão Geral da Arquitetura
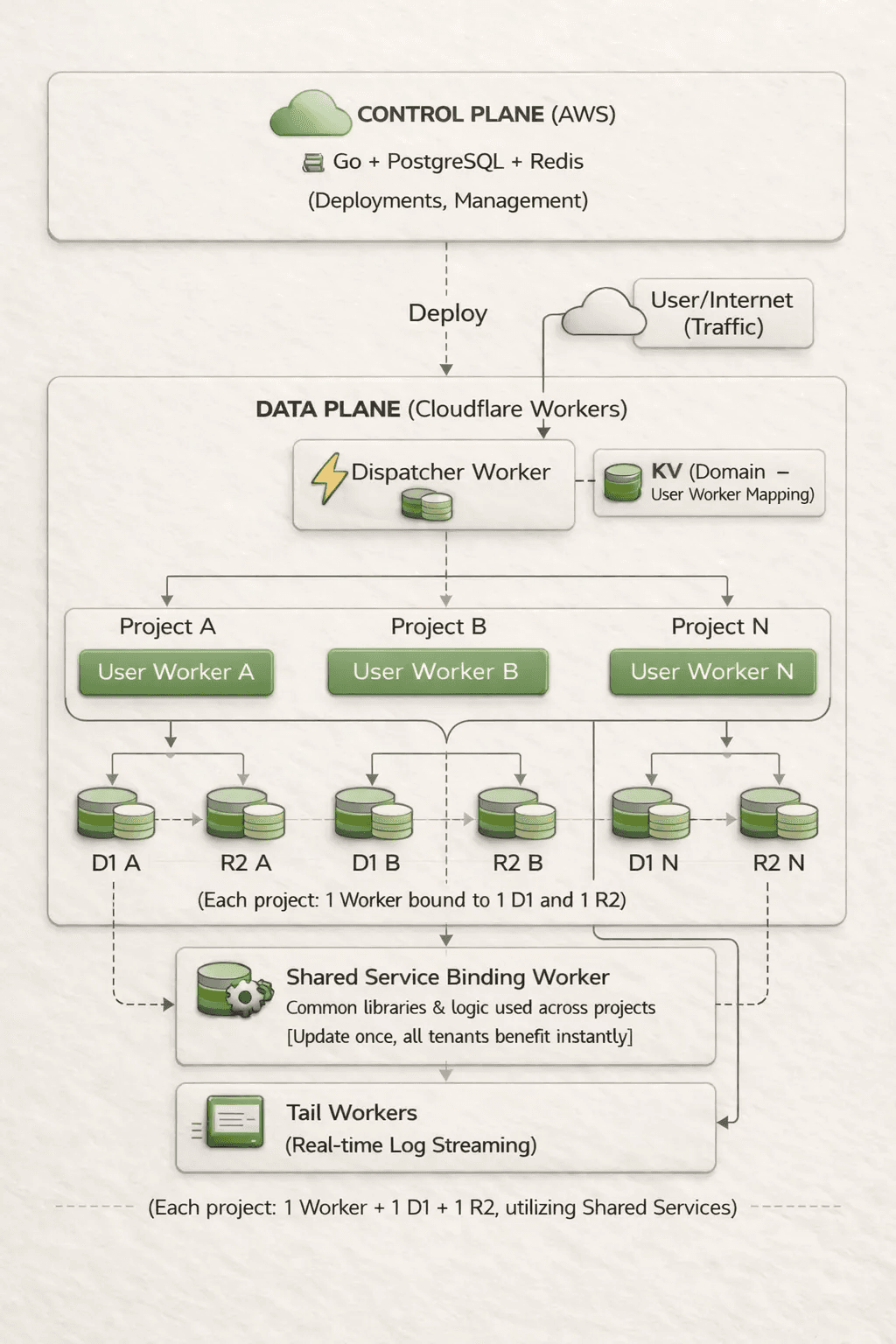
O YouBase roda em uma arquitetura híbrida. O plano de controle (Go, PostgreSQL, Redis, Lambda etc.) gerencia criação de projetos, implantações, faturamento e administração. O plano de dados roda inteiramente no Cloudflare Workers.
Cada projeto recebe seu próprio Worker com um banco D1 dedicado e um bucket R2 dedicado. Não há banco de dados compartilhado nem armazenamento compartilhado. Os bindings são por tenant, portanto, se um Worker se comportar mal, ele não pode acessar o estado de outro tenant.
Um Worker dispatcher roteia as requisições recebidas para o Worker do tenant correto usando mapeamentos de domínio armazenados no KV. Também executamos um Worker compartilhado que fornece lógica comum por meio de Service Bindings, incluindo validação, regras de faturamento, utilitários de framework e feature flags.
Não gerenciamos regiões, réplicas ou pools de nós. Tudo roda automaticamente em mais de 300 localizações da Cloudflare.
Apoiando-se nos Ombros da Cloudflare
Workers for Platforms: Multi-Tenancy Sem Orquestração
Precisávamos de multi-tenancy real. Com Kubernetes, isso significaria políticas de rede, pods por tenant, cotas de recursos, gerenciamento de segredos, bancos de dados por tenant e muito overhead operacional.
O Workers for Platforms oferece isolamento multi-tenant como um recurso nativo do runtime. Cada workspace recebe um namespace de dispatch com seus próprios Workers e bindings. Nosso dispatcher lê os mapeamentos de domínio do KV e encaminha as requisições para o Worker correto:
const workerName = getWorkerNameFromHostname(url.hostname);
const dispatcher = getDispatcher(url.hostname, env);
const backendWorker = dispatcher.get(workerName);
return await backendWorker.fetch(request);
Cada Worker roda em seu próprio isolado V8. Os tenants não podem acessar os bindings ou a memória uns dos outros. Não há sistema de arquivos compartilhado nem ambiente compartilhado.
O que nos surpreendeu não foi o isolamento em si, mas o quão pouca infraestrutura precisamos configurar. Não provisionamos clusters. Não configuramos redes. Não escolhemos regiões. Criamos namespaces e implantamos Workers.
A principal dificuldade aqui foi depurar o roteamento de namespace. Falhas no caminho de dispatch frequentemente aparecem como erros genéricos de fetch com contexto de stack limitado. Acabamos adicionando cabeçalhos de correlação para rastrear requisições do dispatcher, ao Worker do tenant, ao Worker compartilhado.
Mesmo com essa aspereza, essa abordagem foi dramaticamente mais simples do que rodar Kubernetes para código não confiável e gerado dinamicamente.
D1 + Session API: Consistência na Borda
Bancos de dados na borda frequentemente trocam consistência por latência, e esse tradeoff não era aceitável para o nosso caso de uso.
A Session API do D1 resolve isso com bookmarks. Após cada escrita, o banco retorna um bookmark (uma posição no log de transações). Se você enviar esse bookmark na próxima requisição, o D1 garante que você lerá suas próprias escritas:
const BOOKMARK_HEADER = "x-es-sticky-session-db-bookmark";
const bookmark = request.headers.get(BOOKMARK_HEADER) || "first-primary";
const session = env.D1.withSession(bookmark);
response.headers.set(BOOKMARK_HEADER, session.getBookmark());
Passamos bookmarks por cabeçalhos de requisição. Nosso framework os extrai, cria sessões D1, executa queries e retorna o novo bookmark.
Isso nos dá garantias sólidas de read-after-write sem servidores de coordenação. Todas as escritas vão para o primário para consistência. Leituras vão para a réplica mais próxima para velocidade. Se uma réplica ainda não alcançou seu bookmark, ela aguarda.
Operacionalmente, isso foi muito mais simples do que gerenciar réplicas do PostgreSQL e depurar lag de replicação entre regiões.
Service Bindings: Lógica Compartilhada com Atualizações Instantâneas
O problema operacional que mais nos preocupava era atualizar a lógica compartilhada à medida que o número de Workers crescia.
Regras de segurança. Validação. Faturamento. Rate limits. Feature flags.
A resposta tradicional são atualizações graduais em todos os Workers de tenants.
O Service Bindings nos permite rodar um único Worker compartilhado que os Workers de tenants chamam via RPC nativo. Não há camada HTTP, não há autenticação por token, e o overhead é sub-milissegundo.
Usamos esse Worker compartilhado para:
- Validação de SQL
- Cálculos de faturamento
- Rate limiting
- Feature flags
- Utilitários de framework
- Regras centrais de negócio
- Outras preocupações de infraestrutura compartilhada
Quando atualizamos esse Worker, todos os tenants imediatamente veem o novo comportamento.
Essa é a peça que removeu a maior parte do burden operacional. Hoje, uma grande fração das requisições de tenants passa pelo Service Bindings.
Observabilidade: Tail Workers e Analytics Engine
Não podíamos pedir aos usuários para instrumentar logs. Agentes de IA geram código que pode travar, entrar em loop ou se comportar de forma estranha. Precisávamos de logs e métricas que funcionassem "fora da caixa".
Os Tail Workers capturam saída do console, exceções, metadados de requisições e informações de temporização. Construímos um serviço de ingestão que armazena esses eventos em buffer e os transmite para clientes via SSE. Os usuários executam edgespark log tail e veem saída ao vivo com latência sub-segundo.
O Analytics Engine cobre o lado das métricas. Rastreamos dimensões por projeto, por domínio e por endpoint. Sistemas tradicionais falham nesse nível de cardinalidade.
env.ANALYTICS_ENGINE.writeDataPoint({
blobs: [projectId, environment, customDomain, method, status],
doubles: [cpuTimeMs, wallTimeMs],
indexes: [endpoint]
});
As escritas são não-bloqueantes, e os resultados podem ser consultados via SQL sem explosão de cardinalidade.
Usamos isso para dashboards, faturamento, relatórios de uso e rate limiting.
Infraestrutura de Suporte: R2 e KV
O R2 fornece armazenamento de objetos compatível com S3. Cada projeto recebe um bucket dedicado. URLs pré-assinadas, uploads multipart e streaming funcionam como esperado.
O KV armazena mapeamentos de roteamento domínio-para-worker. O dispatcher consulta o KV em cada requisição e as atualizações se propagam globalmente em segundos.
Por Que a Plataforma Integrada Importa
Essa integração foi importante na prática porque não passamos semanas conectando Lambda, RDS, S3 e API Gateway. Não escrevemos lógica de connection pooling nem configuramos endpoints de VPC. Não configuramos políticas IAM entre serviços nem rodamos nosso próprio banco de dados de séries temporais para métricas.
Os Workers chamam D1 e R2 por meio de bindings. O Service Bindings conecta Workers com RPC nativo. O KV gerencia o roteamento. Os Tail Workers capturam logs. O Analytics Engine ingere métricas. As peças se encaixam de forma limpa.
Na prática, isso significou que passamos a maior parte desses dois meses construindo produto em vez de infraestrutura.
Lições Técnicas
Éramos céticos em relação ao SQLite na borda, mas o D1 com a Session API nos provou errados. Ele nos deu dados globais e consistentes com menos complexidade operacional do que réplicas do PostgreSQL.
Multi-tenancy se tornou um problema de configuração em vez de um problema de arquitetura. Quando o runtime suporta isolamento por meio de isolados V8 e namespaces de dispatch, você não precisa construir o isolamento por conta própria.
O Service Bindings resolveu o problema operacional de atualizar lógica compartilhada. Uma implantação atualiza regras de segurança, utilitários e funcionalidades centrais em todos os tenants.
As restrições da plataforma na verdade melhoraram nosso design. Sem processos de longa duração. Sem sistema de arquivos. SQLite em vez de Postgres. Essas restrições nos empurraram em direção a padrões mais simples e confiáveis.
A parte difícil não foi o Cloudflare em si — foi o comprometimento com ele. Passamos mais tempo avaliando alternativas do que depurando problemas em produção.
Também esperávamos que a observabilidade levasse semanas. Os Tail Workers e o Analytics Engine nos colocaram em funcionamento em poucos dias.
Depurar Workers distribuídos em escala é mais difícil do que esperávamos. As ferramentas não são tão maduras quanto ambientes de servidor tradicionais. Mas o tradeoff de simplicidade operacional vale a pena.
Limitações Atuais
O D1 tem um limite de 10 GB por banco de dados. Isso funciona bem para a maioria das aplicações em produção, mas não para cargas de trabalho intensivas em dados.
Os Workers têm um limite de 300 segundos de tempo de CPU por requisição HTTP. Tarefas de longa duração requerem padrões assíncronos ou processamento em segundo plano.
WebSockets requerem Durable Objects para estado persistente. A arquitetura atual é apenas requisição-resposta, portanto funcionalidades em tempo real como presença ou cursores ao vivo precisam de infraestrutura adicional.
O live tail atualmente suporta apenas ambientes de staging. Retenção e consulta de logs em produção requerem sistemas separados de armazenamento e indexação.
Estas são restrições da plataforma com as quais trabalhamos hoje.
Roadmap Futuro
Estamos integrando Cron Triggers para jobs de segundo plano agendados, como limpeza de banco de dados, geração de relatórios e agrupamento de notificações.
Para colaboração em tempo real, estamos avaliando Durable Objects para gerenciamento de WebSocket, sistemas de presença e sincronização de estado.
Para suportar aplicações intensivas em dados, estamos adicionando suporte a PostgreSQL e MySQL, com Workers de tenants acessando bancos externos via pooling seguro.
Também estamos expandindo o uso do Analytics Engine para métricas de negócio de nível superior, como popularidade de endpoints de API, uso de funcionalidades e padrões de erros.
O plano de dados na borda já escala globalmente. Esses esforços se concentram nas capacidades do plano de controle e nas lacunas remanescentes da plataforma à medida que os primitivos subjacentes continuam evoluindo.
Conclusão
Construímos o YouBase no Cloudflare Workers porque não queríamos passar seis meses em infraestrutura antes de publicar o produto. Dois meses depois, estávamos em produção com cold starts em milissegundos, leituras consistentes na borda e observabilidade automática.
Ainda há arestas. Depurar Workers distribuídos é mais difícil do que depurar um monólito, e alguns limites da plataforma exigem workarounds. Estamos construindo soluções híbridas para as áreas onde os Workers ainda não se encaixam perfeitamente.
Mas não precisamos reconstruir a infraestrutura central desde o lançamento. Até agora, ela suportou a carga de trabalho para a qual foi projetada. Quando precisamos atualizar todos os tenants, levou cerca de 30 segundos. Esse tradeoff foi o que importou.
Apêndice Técnico: Tecnologias Cloudflare Utilizadas
Stack do Plano de Dados:
- Cloudflare Workers – Computação serverless baseada em isolados V8 na borda
- Workers for Platforms – Implantação de workers multi-tenant com namespaces de dispatch
- Cloudflare D1 – Banco de dados na borda baseado em SQLite com Session API para consistência
- Cloudflare R2 – Armazenamento de objetos compatível com S3 com acesso global na borda
- Cloudflare Service Bindings – Comunicação worker-a-worker estilo RPC de baixa latência
- Cloudflare KV – Armazenamento chave-valor para roteamento de domínios
- Tail Workers – Streaming de logs em tempo real e observabilidade
- Analytics Engine – Métricas de cardinalidade ilimitada com queries SQL
Stack do Plano de Controle:
- Runtime: Go com framework Hertz
- Banco de dados: PostgreSQL para estado do plano de controle
- Cache: Redis para sessões e rate limiting
- Serverless: AWS Lambda para tarefas assíncronas
Framework para o Usuário Final:
- Framework HTTP: Hono (leve, otimizado para borda)
- ORM: Drizzle ORM (SQL type-safe com adaptador D1)
- Autenticação: Better Auth com suporte nativo a D1


