Pessoas em todo o mundo estão sofrendo de Fadiga do Gradiente Roxo. E sabemos quem culpar. Cinco anos atrás, o criador do Tailwind CSS — o framework que basicamente sustenta a web moderna de IA — tomou uma decisão fatídica: definiu a cor padrão da interface como bg-indigo-500. Uma escolha que, sem que ele soubesse, definiria a estética de toda uma geração de IA.
Entra a Anthropic, que adotou essa estética roxa e foi longe com ela. O modelo principal deles, o Claude Sonnet, parece ter uma conexão profunda e espiritual com essa cor. Não importa o quanto você detalhe seu prompt de design ou implore, ele sempre entrega outro site com gradiente roxo.
Usamos muito o Sonnet aqui no YouWare. Tanto que nosso próprio site começou a parecer uma homenagem à cor roxa. Esta é a história de como nos libertamos.
O Curativo do Botão "Boost"
Nosso primeiro plano de fuga foi uma funcionalidade que chamamos de "Boost".
Os prompts de sistema para agentes de IA são longos e exigentes. Não dá pra simplesmente dizer a uma IA para "deixar bonito" e esperar uma obra-prima. Então, criamos um modo especial chamado "Boost". Quando o usuário clica nele, o agente muda para um conjunto selecionado de diretrizes de design moderno, dando ao projeto uma atualização estética instantânea — e, mais importante — um exorcismo da praga roxa.
O Boost é uma ótima funcionalidade que funciona muito bem, especialmente em projetos novos. Mas conforme as pessoas foram usando, aprendemos duas coisas:
Compartilhe
Pronto para criar?
É um Grande Compromisso: Clicar em "Boost" é como reformar todos os cômodos da sua casa de uma vez. É um salto de fé. Como os usuários nem sempre sabiam o que esperar, alguns hesitavam em aplicar uma mudança tão grande a um projeto no qual já haviam investido esforço.
Pode Ser Disruptivo: Em sites mais complexos, uma reformulação completa do sistema de design pode causar instabilidade. Embora não quebre o site, pode introduzir deslocamentos inesperados de layout ou inconsistências de estilo que exigem ajustes manuais.
Embora o Boost ainda seja uma ferramenta valiosa no nosso arsenal — perfeita para iniciar novos projetos com estéticas fortes e não-roxas — ele nos ensinou uma lição crucial: prompting e pós-processamento têm limites. Um curativo pode cobrir uma ferida, mas não pode curá-la. A verdadeira batalha precisava ser travada no modelo base em si.
Se Você Não Consegue Avaliar, Não Consegue Melhorar
Mas como travar uma batalha no nível do modelo? Você não pode consertar o que não consegue medir. Para encontrar um modelo base melhor — um que não defaulte para gradientes roxos — precisávamos de uma forma rigorosa de comparar modelos objetivamente. Precisávamos de um framework de avaliação sistemático.
No YouWare, tratamos avaliações com certa reverência. Construímos uma plataforma de avaliação automatizada para uso interno. Não é sofisticada, mas é eficaz.
Quando um novo modelo é lançado, bastam alguns cliques para rodar um conjunto completo de casos de teste nele. Usamos a técnica de LLM-como-juiz para pontuar os resultados e montamos nosso próprio ranking interno, algo parecido com o LMArena.
Para resolver o inevitável viés de um juiz de IA, também rotulamos os dados nós mesmos. Isso mantém o sistema honesto. Esse esforço nos dá um sistema robusto de avaliação automatizada que cobre todos os aspectos da geração de sites, com subpuntuações para:
Visual: Ex.: Parece que foi projetado em 2025 ou em 2015?
Funcional: Ex.: O botão "Fale Conosco" funciona?
Requisitos: Ex.: O sistema lembrou que você pediu um "design minimalista e brutalista para uma cafeteria de gatos"?
Por muito tempo, o Claude foi o rei dos nossos benchmarks internos.
Seus designs eram completos. E ele tinha seu próprio sistema de design coerente (ainda que roxo), algo que a maioria dos outros modelos não tinha.
Uma Nova Esperança (e Uma Nova Dor de Cabeça)
Em 7 de agosto de 2025, o GPT-5 foi lançado.
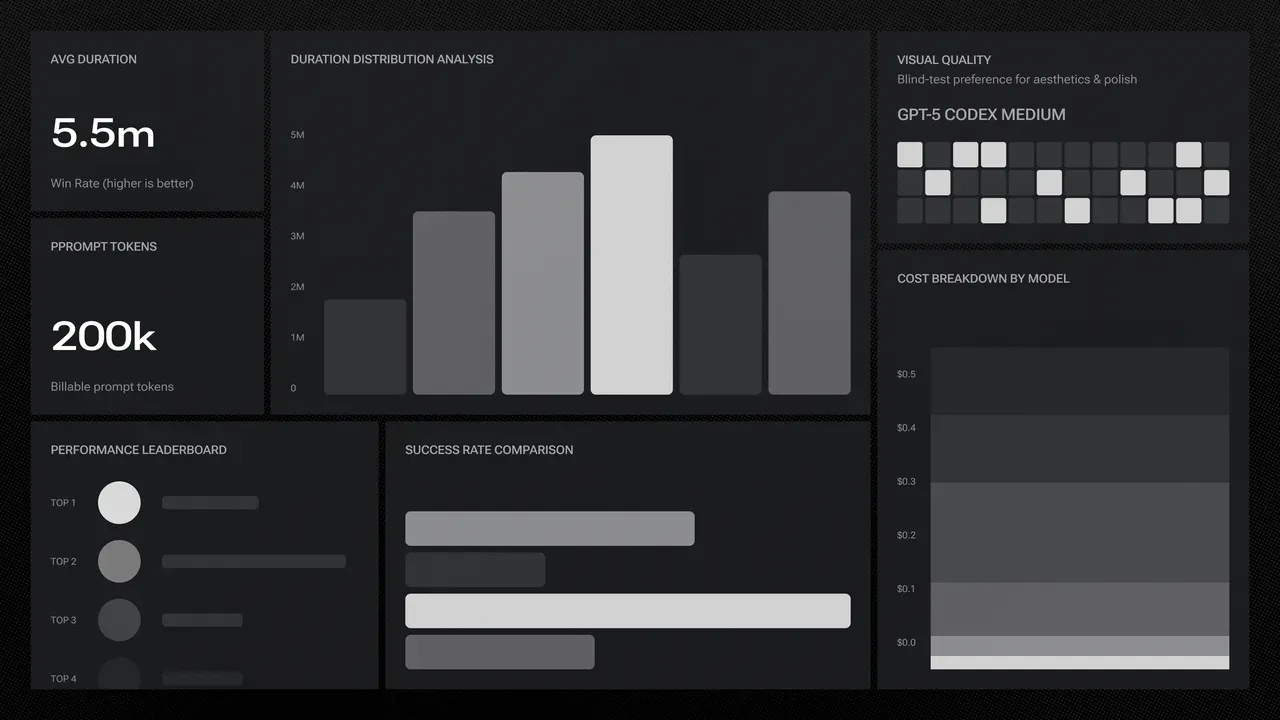
Testamos imediatamente, mas os resultados foram agridoces. Foi o primeiro modelo a chegar perto do nível de qualidade do Sonnet. Mas era apenas a variante gpt-5-high. Pense nisso como colocar as configurações gráficas de um videogame no modo "Ultra" — os visuais são deslumbrantes, mas a taxa de quadros despenca. E era lento. Muito lento mesmo.
Claude Sonnet: 5 a 6 minutos para gerar um site.
GPT-5-High: Quase 20 minutos.
Vinte minutos é uma eternidade no tempo da internet. Isso tornava o GPT-5-High inutilizável. Mas em setembro, um novo desafiante apareceu: o GPT-5-Codex.
A empresa inteira se apaixonou pelo modelo "Codex" no CLI imediatamente. Era rápido, inteligente e conseguia ajustar seu raciocínio de forma dinâmica. Mas não havia API. Então, esperamos. Uma semana depois, a API foi disponibilizada, e rodamos nossas avaliações.
Quando os resultados chegaram, achamos que nosso sistema estava quebrado. Pela primeira vez, um modelo havia destronado o Claude. Era mais rápido, mais barato e, o mais importante, sua pontuação visual destruiu a do Sonnet.
Para ter certeza, revisamos os resultados lado a lado manualmente. Eram 22h, e o escritório estava cheio de exclamações de "Caramba!" e "Não acredito!". O Codex estava gerando sites com designs modernos, premium e com identidade visual forte. Pareciam feitos por humanos. No dia seguinte, colocamos o Codex em produção. O reinado roxo havia finalmente acabado.
A Última Milha É Sempre a Mais Estranha
Então, tivemos nosso final feliz, certo? Bom, não tão rápido.
O Codex é um gênio, mas de um tipo estranho e psicodélico. As pessoas no X (antigo Twitter) parecem concordar.
https://x.com/willccbb/status/1973178973027967132
É um modelo fortemente ajustado por RL que é excepcional em programação e bem ruim em todo o resto.
Ele é estranho com chamadas de ferramentas. Dê a ele uma ferramenta, e ele vai encontrar a forma mais inesperada de usá-la. Já o vimos tentar usar nossa ferramenta de navegação web para fazer requisições HTTP à documentação oficial do Node.js.
Ele pensa demais em tudo. Faça uma pergunta difícil, e ele pode passar uma hora revisando cada arquivo do seu projeto antes de dar uma resposta.
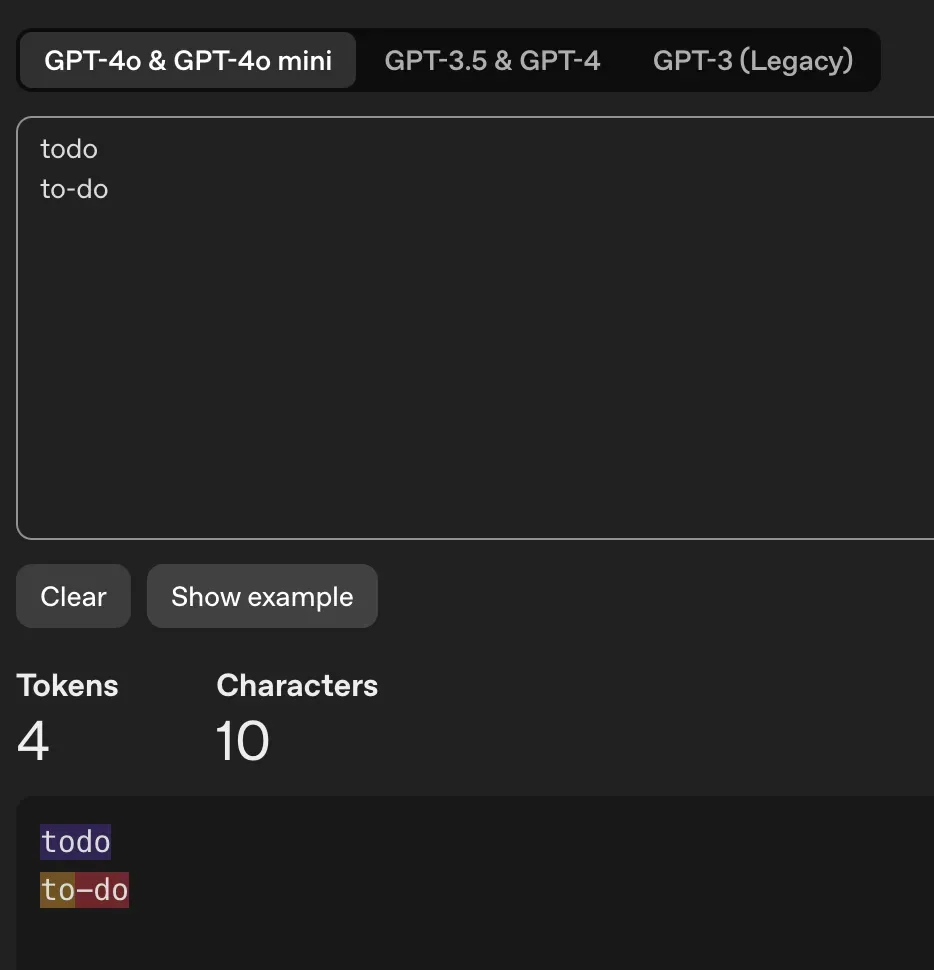
Ele começa a falar espanhol aleatoriamente. Esse foi o bug mais estranho. O usuário estaria digitando em inglês, e o Codex responderia em espanhol fluente. Passamos semanas depurando isso. A causa? Uma das nossas ferramentas internas chamava-se todo_write. "Todo" é uma palavra comum em espanhol que significa "tudo". O modelo ficava confuso com o nome dessa ferramenta. Mudamos para to_do_write, e o problema desapareceu.
Nos olhos do GPT, 'todo' é uma palavra só, 'to-do' são duas palavras.
Como o Codex é tão poderoso e ao mesmo tempo tão peculiar, tivemos que reengenheirar todo o nosso sistema de prompting e ferramentas para acomodá-lo. O Guia de Prompting do GPT-5-Codex da OpenAI foi um salva-vidas, enfatizando que o Codex não é um substituto direto para outros modelos.
A Vida Depois do Roxo
Após semanas de trabalho intenso, otimizamos nosso sistema para o Codex, reduzindo o tempo de geração em 50% e os custos em 70%, mantendo o desempenho.
Foi uma jornada longa e estranha, mas valeu a pena. Agora, nossos usuários podem obter um site com um design de alto nível, sem roxo, por apenas alguns centavos. E acreditamos que isso faz toda a diferença.
Como Matamos de Vez o Gradiente Roxo nos Frontends de IA